We're officially a Great Place To Work® certified company, India | 2026–27
Mayank Patel
Nov 4, 2025
6 min read
Last updated Nov 4, 2025

AI-powered search is redefining how customers discover products online but many ecommerce brands are still held back by outdated Product Information Management (PIM) systems. Traditional PIMs were never built for the demands of modern, semantic, and vector-based search. They store data, but they don’t understand it.
This article explores why legacy systems fail to deliver accurate, AI-driven search experiences and outlines a clear roadmap to modernize your product listings. From cleaning up inconsistent metadata and normalizing taxonomies to integrating with vector databases and semantic search engines, you’ll learn how to transform your PIM into an intelligent foundation for next-generation ecommerce discovery.
Legacy PIM systems were not designed with AI search in mind. Many B2B organizations still rely on older PIM or even ERP/catalog systems that manage product data in a rudimentary way. While these systems may serve as a basic “single source of truth” for product specs, they often lack the structure and richness needed for AI to truly understand and use the data.
In older or poorly governed PIMs, product attributes are often spotty and non-standardized. Different product lines might use varying names for the same attribute (“Size” vs “Dimensions”), values may be formatted inconsistently (e.g. some lengths in inches, others in mm), and many fields may be left blank.
Missing or non-uniform attributes lead to poor search recall and irrelevant results, for instance, if half your catalog omits a “material” attribute, an AI search for “stainless steel bolts” might miss many relevant items. Without complete, clean data, AI cannot infer product relevance or answer detailed queries.
A well-defined product taxonomy (categories, subcategories, attribute schema) is important for both humans and AI to navigate a catalog. Yet many PIMs either have outdated, fragmented taxonomies or none at all beyond basic category groupings.
In B2B, this is especially problematic. Products might be categorized differently by different teams or channels, leading to a disjointed structure. For example, the same item could be classified as “Protective Gear > Safety Glasses” in one system, but just lumped under “Accessories” in another.
This fragmentation creates confusion and poor search results, since semantic engines can’t easily learn relationships or compare products across inconsistent groups. Traditional PIMs also struggle to accommodate new attributes or categories without heavy manual rework.
In many traditional PIM workflows, any improvement to product data (like adding synonyms or updating categorizations) is a manual, rule-based process. If a new synonym or industry term emerges, someone has to manually update a mapping or keyword list in the system.
These manual processes break down at scale and speed as catalogs grow to thousands of SKUs and user behavior shifts rapidly, rule-based systems can’t keep up. For example, if buyers start searching using a new abbreviation for a product spec, a conventional PIM won’t capture that unless an admin notices and adds it.
AI-powered search, on the other hand, thrives on dynamic learning. Traditional PIMs typically aren’t integrated with AI or machine learning that could adapt taxonomies or attribute mappings based on real customer behavior. The result is stagnant data: the PIM’s view of your products doesn’t evolve with how customers talk about or search for them.
This is one reason keyword-only search fails for B2B buyers who use jargon and synonyms that a static system doesn’t understand. Traditional PIMs also often operate in silos, separate from analytics or search systems, so they don’t “learn” from search queries at all. In contrast, an AI-ready approach might mine search logs and feedback to continually refine product data (e.g. adding a new synonym or adjusting a category).
Also Read: How Horizontal Integration Helps B2B Marketplaces Grow Faster and Smarter
Upgrading your PIM for AI-powered search is not a single flip of a switch, but a multi-step journey. It involves re-architecting how your product data is structured, enriched, and governed. Below is a step-by-step roadmap covering the key facets you should focus on:
To lay the groundwork, start by overhauling your product data schema. The goal is to impose consistency and structure where it may have been lacking. This involves creating standardized attribute definitions, cleaning up values, and organizing products into a coherent taxonomy.
Begin with a data quality audit. Identify inconsistencies, duplicates, or ambiguities in your current product attributes. For example, you might find that “Width” and “W” are both used as fields for essentially the same data, or that one brand’s products list “Material” while another uses “Primary Composition”.
Decide on master attribute names and formats and apply them universally. If units of measure vary, choose a canonical unit for each measurement type (e.g. always use millimeters for dimensions internally) and convert or store equivalents.
Consistent attribute formatting is super important. Normalizing these attributes not only helps with search filters (faceted search) but also ensures that semantic algorithms know two values are the same (e.g. “2 inch” and “50.8 mm” should map together).
Define value ranges and allowable formats to prevent future drift. Essentially, you want a single source of truth for each attribute; one name, one format, and ideally no empty values on important fields. This master schema might be captured in a data dictionary or directly enforced in your PIM via validation rules.
Next, tackle your product categorization. If your categories are outdated or inconsistent across channels, now is the time to normalize them. Develop a hierarchical taxonomy that makes sense for your catalog size and product types. A best practice is to start with customer intent and logical groupings.
Analyze how customers naturally segment your products through search query clustering, analytics on frequently used filters, or industry standards. For instance, in a hardware B2B context, buyers might think first in terms of use-case (“Electrical > Wiring > Connectors”) rather than internal divisions (“Product Line A vs B”).
Align your taxonomy to how users conceptualize the domain. Ensure each level of the hierarchy is unambiguous and that products are not straddling multiple categories in confusing ways. Also, search engines like Google gain clarity on your site structure, helping SEO.
Modern AI can even assist here: machine learning can analyze product attributes and customer behavior to suggest optimal category groupings, a process known as AI-driven taxonomy standardization. The benefit is a taxonomy that’s informed by how customers actually browse and search, rather than just internal opinion. Once defined, enforce the taxonomy in your PIM (no rogue categories) and map legacy categories to the new scheme.
Also Read: When Your B2B Ecommerce Site Doesn’t Talk to Your ERP
With a structured dataset in place, the next step is to ensure your PIM bridges the gap between how you describe products and how customers search for them. This is where mapping synonyms, slang, industry jargon, and user queries to your official product data becomes critical.
Even the best product content might use different wording than a customer’s query. For example, your PIM might list an item as “polycarbonate safety glasses”, but a buyer searches for “shatterproof goggles”. AI-powered search can handle such discrepancies if it has a knowledge of synonyms and intent mapping. Here’s how to upgrade your PIM (and search integration) to align with customer language:
In traditional search, teams often maintain a synonym list manually (e.g. telling the search engine that “PTFE” is equivalent to “Teflon”). For AI search, you want this to be more expansive and dynamic. Start by aggregating all the term variations that customers might use for your products.
Sources include search query logs, website analytics (e.g. internal searches that returned zero results), customer reviews (for colloquial terms), and input from sales/support who hear customer lingo. Mine these data sources to find patterns, perhaps you discover that “SS” often appears meaning “stainless steel” in queries, or that users type “grinder” for what your catalog calls “milling machine”.
Create a synonym dictionary that maps these to your canonical terms. Modern AI can assist by clustering similar terms from large text corpora; some PIM systems allow uploading synonym lists or even auto-detecting them from usage data.
For instance, if your logs show “O-ring” and “seal” often lead to the same clicks, that’s a relationship to formalize. Feed these synonyms into both your PIM (as metadata) and search engine configuration. Your PIM could have a field for “synonyms” on each product or attribute, or you maintain a separate thesaurus file that the search index references. Without a synonym map, a search engine might return “no results” even when the right product exists.
Go beyond one-to-one synonyms and consider the intent behind queries. Semantic search engines attempt to parse user intent (e.g., “best for outdoor use” implies looking for weather-resistant features). Your PIM can support this by having attributes or tags that align with intents.
For example, have a boolean attribute “Outdoor Rated” which you set to true if a product is weatherproof; then map likely intent phrases (“for outdoor”, “weatherproof”, “rugged”) to trigger filtering or boosting on that attribute. Some of this happens on the search engine side (where AI models determine that “outdoor” = requires Outdoor Rated true), but it’s up to your data to have the structure to respond.
If you enriched content, you likely added many of these phrases into descriptions. Now ensure that if a user asks a question, the answer lives in the data. Integrating your PIM with a vector search or AI Q&A system will mean user queries can be answered from the product data.
So, if customers often ask “What’s the difference between X and Y?”, consider adding a comparative note or a dedicated field in PIM capturing that (even linking related products). Another example: map units and standards to what customers use. If European customers search by metric and Americans by imperial, make sure your PIM lists both, or that your search layer can convert on the fly (which it can if your attributes are normalized and synonyms set up for “inch” vs “mm” as done in Step 1).
A concrete tactic is to use customer query analytics: take the top N search queries on your site (and maybe on external search leading to your site), and systematically verify that your PIM has data to satisfy those queries. If “high-temperature gasket” is a frequent query, do you have “Max Temperature” recorded for all gaskets? If not, add it (enrichment again) and ensure “high-temperature” maps to that attribute range.
Traditional keyword synonym lists are useful, but AI offers a more robust way: vector embeddings can naturally encode similarity between words and phrases without explicit rules. For instance, an AI model might learn that “weatherproof” is close to “water-resistant” in vector space. Ensure your upgraded search stack takes advantage of this.
In practice, this means when you feed product data to a vector search engine, include all the rich textual info you’ve built: descriptions, attributes, etc. The model will then inherently connect many synonyms. For example, OpenAI or ELSER embeddings might place “SS” and “stainless” close together if your data has examples of both referencing steel.
To maximize this, consider adding common alternate terms into your content (which you may have done in enrichment). A tip from B2B search implementations is to use field-aware embeddings, e.x., have one vector for material attributes, one for product names, etc., to avoid noise.
That might be a technical detail, but the idea is to ensure the context of terms is captured. The benefit: embeddings can decode jargon on the fly; they map terms like “PTFE” and “Teflon” close to each other, meaning the system can retrieve relevant items even without an explicit synonym rule.
Many modern search platforms (like Algolia Neural, Elasticsearch dense vectors, or custom setups with Python and Pinecone) allow hybrid retrieval: using both traditional synonyms and vector similarity. Aim to configure your system this way: synonyms handle the critical exact mappings (ensuring no zero-result for simple cases), while vectors handle the fuzzy intent matches (“red running shoes” ≈ “scarlet sneakers”).
Up to now, our focus has been on getting the PIM data itself into shape. The next step is more systems-focused: making sure that your PIM can feed and work in tandem with modern AI-powered search infrastructure. Semantic and vector search engines are fundamentally different from traditional SQL or simple text indexing, they often require additional components like embedding generation, vector storage, and hybrid query handling. Here’s how to ensure a smooth connection between your PIM and an AI-centric search stack:
Traditional search indexes (like Solr or the classic Elastic index) can’t handle the high-dimensional vectors used in AI similarity search. You’ll need a vector database (e.g. Pinecone, Weaviate, Vespa) or an updated search engine that supports vectors (Elastic 8.x with KNN, or OpenSearch, etc.). The first step is to choose your solution and ensure your PIM can export data to it.
Many ecommerce teams are now using a hybrid approach: for example, keep using Elasticsearch for keyword search and faceted filtering, but layer in a vector engine for semantic matches. Make sure your PIM can supply a complete feed of product content to whichever engine you use. This often means developing an ETL (extract/transform/load) pipeline or real-time sync.
If your PIM is modern, it likely has APIs or connectors. For instance, Algolia’s AI Search or Azure Cognitive Search can connect to PIM feeds and automatically generate embeddings for each record. If you roll your own (say, using Python to generate embeddings via an LLM model and store in Pinecone), make sure you have a mechanism to keep it updated as products change.
The goal is that for every product in PIM, there’s a corresponding vector representation in the search index that encapsulates its meaning. Compatibility here also means handling data types: the PIM might store text, images, attributes separately, whereas a vector search might expect a single blob of text.
You may need to concatenate fields (like “title + description + attributes”) when generating embeddings, or create multiple embeddings per product (one for text, one for image). Plan this out and test different approaches for search relevance. The investment is worth it.
For most B2B scenarios, the best practice is not to rely solely on vector search but to combine it with traditional search. Ensure your search architecture supports this. This might mean running two queries in parallel: one against the keyword index (e.g. Elastic) and one against the vector index, then merging results.
Techniques like reciprocal rank fusion (RRF) are commonly used to blend the two result sets. Implementing RRF or a custom reranker is an added complexity but yields big gains in relevance. It ensures the “best of both worlds” (exact matches for those who know part numbers, plus semantic matches for natural language queries).
Many search platforms are starting to add this blending. For example, Elasticsearch’s Semantic Search capabilities allow a query to include both a vector similarity clause and a traditional BM25 clause. Algolia also offers a hybrid retrieval where their AI re-ranks keyword results using vectors. When upgrading your PIM, confirm that your data exports include all the fields needed for both types of search.
For instance, you may need to maintain a separate keyword index of certain fields (like SKU, part number, short name) for exact matching. Don’t throw away the structured nature of your data, facets and filters (e.g. filter by brand, by price) should still work alongside AI search.
A well-prepared PIM will have those facets clean (from Step 1’s normalization), and your search engine can use them to filter vector search results (many vector DBs support returning an ID list that you then intersect with a filtered set from a traditional DB). Setting up this integration might require help from a search relevancy engineer or using a service like Algolia Neural or Azure Vector Search if you want less custom coding.
Another compatibility aspect is hooking up a re-ranking model on your search results. Often, after retrieving a set of candidates via keyword/vector, an AI cross-encoder re-ranker can be used to fine-tune the ordering (e.g., BERT or GPT style model that looks at query-product pairs to score relevance).
This may be advanced, but many off-the-shelf solutions exist (Google’s Semantic Kernel, AWS Kendra’s ML ranking, etc.). The PIM’s role is indirect here, but ensure that product data fed to the re-ranker is sufficient. That means consistent titles, relevant attributes available as context, etc., which we’ve addressed in prior steps.
If going this route, you might have to deploy a model or use a SaaS API for re-ranking. The benefit observed in industry is significant. Just remember to cache and monitor performance, since these models can add latency. It’s a decision of where to get this re-ranking model (build vs buy) and making sure architecture can handle it. For the businessman in you, the takeaway is that AI can not only retrieve more stuff, but also sort it in a smarter way often yielding a better experience than the old “most relevant by text match” sorting.
")
Why Some Lead Form Fields Kill Conversions (And Which Ones Actually Help)
Most B2B funnels break at the form. Teams keep adding fields like company size, job title, phone number, and budget, hoping better data will improve lead quality. Instead, conversion rates drop and demo requests slow down. What started as a qualification step becomes a friction point. Every additional field increases effort, hesitation, or privacy concerns, quietly pushing legitimate prospects away before they ever submit the form.
Lead forms sit at the centre of the funnel, which creates a constant trade-off. Collect too little information, and sales receive unqualified leads. Collect too much, and potential customers abandon the form. The real challenge is knowing which fields genuinely improve qualification and which ones only create friction. This blog breaks down that difference and explains how to design forms that capture leads without hurting conversions.
Read more: Why Enterprise AI Fails and How to Fix It
Most long lead forms are not designed intentionally. They grow over time. The form becomes a place for data collection rather than a mechanism for moving prospects through the funnel. Understanding why teams add these fields is the first step to identifying which ones actually create value.
Read more: Executive Guide to Measuring AI ROI and Payback Periods
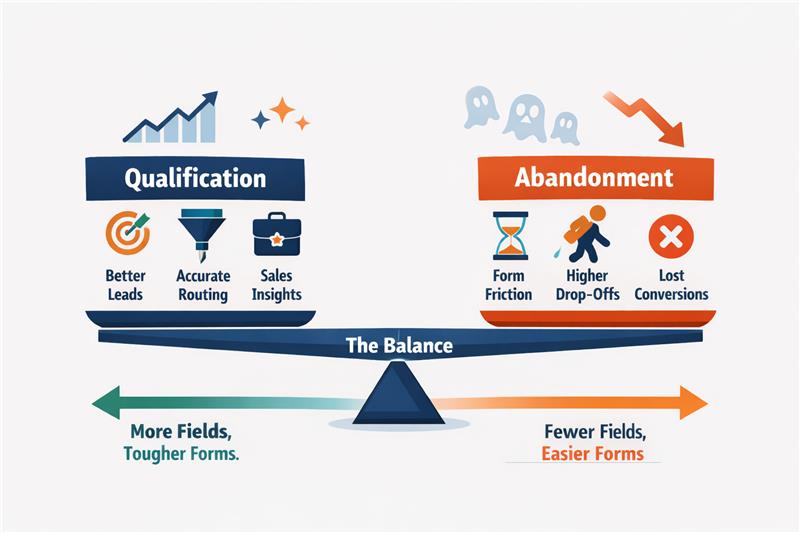
Most B2B teams design forms with a single objective: To improve lead quality. Additional fields are added to capture firmographic data, assess intent, or help sales prioritise outreach. Over time, the form becomes longer, the questions become more detailed, and the assumption remains the same: more information should produce better leads.
This is where the core trade-off emerges.
Understanding this trade-off helps teams evaluate whether a field actually improves decision-making or simply adds friction.
| Aspect | Qualification | Abandonment |
| Definition | The process of identifying whether a lead fits the company’s ideal customer profile or purchasing potential. | The point at which a user leaves the form without submitting it. |
| Purpose in the funnel | Helps sales prioritise leads and allocate time to higher-value opportunities. | Reduces the number of captured leads, weakening the top of the funnel. |
| Typical triggers | Fields like company name, job title, or company size that provide useful context for sales teams. | Long forms, sensitive questions, or complex dropdowns that increase effort or discomfort. |
| User perception | Users feel they are providing relevant information to request a demo or contact sales. | Users feel the form requires too much effort or asks for unnecessary personal or company data. |
| Impact on conversion rates | Moderate qualification fields may slightly reduce conversions but improve lead quality. | Excessive or poorly chosen fields significantly increase drop-off rates. |
| Design implication | Fields should only exist if they help a meaningful sales or routing decision. | Any field that does not influence decisions becomes unnecessary friction. |
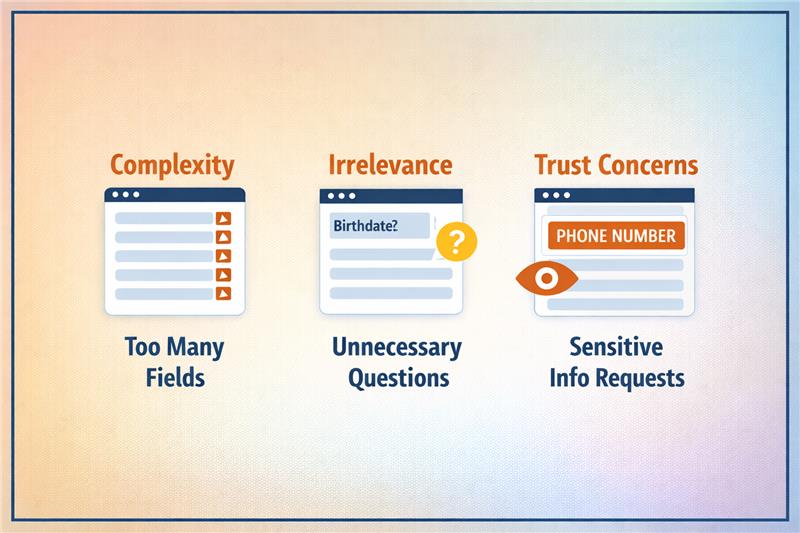
Form abandonment happens when the form introduces friction that feels unnecessary or uncomfortable. Small moments of hesitation accumulate as the user progresses through the form. When the perceived effort becomes higher than the expected value, users exit the flow.
Three behavioural triggers typically drive this drop-off:
Some fields immediately create hesitation because users worry about how the information will be used. Questions that appear sensitive or intrusive increase perceived risk before trust is established.
Trigger: Fields such as phone numbers, revenue ranges, or personal contact details raise concerns about unwanted sales calls or data misuse, prompting users to abandon the form.
Certain questions require users to pause, think, or estimate information they may not know immediately. When a form demands too much mental effort, the completion process slows down.
Trigger: Complex dropdown menus, unclear categories, or questions like company revenue or employee ranges increase cognitive load and discourage users from finishing the form.
Some information is useful later in the sales process but appears too early in the initial conversion step. When advanced qualification questions appear prematurely, users feel they are entering a long evaluation process.
Trigger: Asking detailed requirements, budget ranges, or implementation timelines during the first interaction creates friction because the user has not yet committed to deeper engagement.
The goal is not to eliminate qualification from the form but to focus on fields that deliver decision value without creating unnecessary resistance. When forms prioritise these signals, teams gain useful context while keeping the submission experience manageable for the user.
Read more: How to Deploy Private LLMs Securely in Enterprises
Identifying and removing the right form fields reduce friction while maintaining the information that genuinely supports qualification.
Read more: How to Deploy Private LLMs Securely in Enterprises

The most practical approach is to assess every form field through a signal versus friction lens. Signal represents the decision value the field provides, while friction represents the effort or hesitation it introduces for the user. When teams analyse fields using this framework, it becomes easier to separate necessary qualification questions from unnecessary data requests.
Read more: Modern AI Data Stack Architecture Explained for Enterprises
The objective is to understand how each field affects both conversion behaviour and downstream pipeline outcomes. This requires measuring not only form completion rates but also how those leads progress through the sales process. When testing is done carefully, teams can improve conversion rates without sacrificing qualification quality.
Read more: Personalization vs Borad UX Changes in Conversion Rate Optimization Services
Lead forms should capture decisions, not excess data. Every field must justify its presence by improving routing, prioritisation, or sales context. When forms collect information that does not influence these decisions, friction increases and conversion rates drop. The most effective funnels focus on a small set of high-signal fields that capture intent without slowing users down.
Improving forms requires a disciplined approach: evaluate each field for signal, test changes carefully, and measure both conversion rates and downstream pipeline outcomes. When designed correctly, forms become a fast entry point rather than a barrier. If your funnel is struggling with form friction or qualification trade-offs, Linearloop helps teams design and optimise conversion flows that improve both lead capture and pipeline quality.
Mayur Patel
Mar 11, 20266 min read

How to Optimise Demo Request Flows Without Disrupting Sales Infrastructure
Experimenting with demo request flows is risky for most B2B teams. A small change to a form can break lead routing, override territory rules, double-book SDR calendars, or corrupt CRM records. Since demo requests trigger multiple operational systems at once, many teams avoid testing entirely. This results in high-intent conversion points remaining untouched, even when conversion rates could clearly improve.
Yet demo request forms sit at the most valuable moment in the funnel, when a visitor is ready to talk to sales. Improving this step can directly increase the qualified pipeline. The challenge is running experiments without disrupting routing logic, territory ownership, or calendar availability. This blog explains how teams can test demo request flows safely while keeping their sales infrastructure intact.
Read more: Personalization vs Borad UX Changes in Conversion Rate Optimization Services
Demo request flows sit directly on top of sales infrastructure. The moment a visitor submits a demo request, multiple operational systems activate simultaneously. Because these systems depend on specific fields and routing logic, even small changes to the form can break downstream processes.
Read more: Modern AI Data Stack Architecture Explained for Enterprises
Experimenting with demo request flows can easily disrupt sales operations. These forms sit at the junction of marketing and sales infrastructure, triggering routing engines, CRM records, and scheduling systems simultaneously. When teams modify form fields, qualification logic, or scheduling steps without considering these dependencies, operational failures appear quickly. Leads may route incorrectly, ownership rules can break, and booking flows can fail before a meeting is even scheduled.
The most common issue is incorrect lead assignment. Routing systems rely on specific inputs such as geography, company size, or industry. If experiments remove or change these fields, leads can bypass routing rules and land with the wrong representative. Territory conflicts follow, especially in organisations with strict regional ownership.
These failures affect more than operations. SDR teams experience overloaded calendars or missed follow-ups. CRM data becomes inconsistent when records map incorrectly or duplicate entries appear. Pipeline reporting also suffers because demo requests may not be attributed properly to campaigns or sales teams. Revenue forecasts, conversion analysis, and performance tracking become unreliable. The solution is designing tests that respect routing logic, territory ownership, and sales infrastructure dependencies.
Read more: How to Deploy Private LLMs Securely in Enterprises
Teams often identify friction in demo request flows but hesitate to experiment because these forms sit on top of critical sales infrastructure. Even small UI changes can affect routing rules, territory ownership, or scheduling logic. Many CRO ideas can improve conversions, but if implemented without operational safeguards, they can disrupt CRM workflows and sales execution.
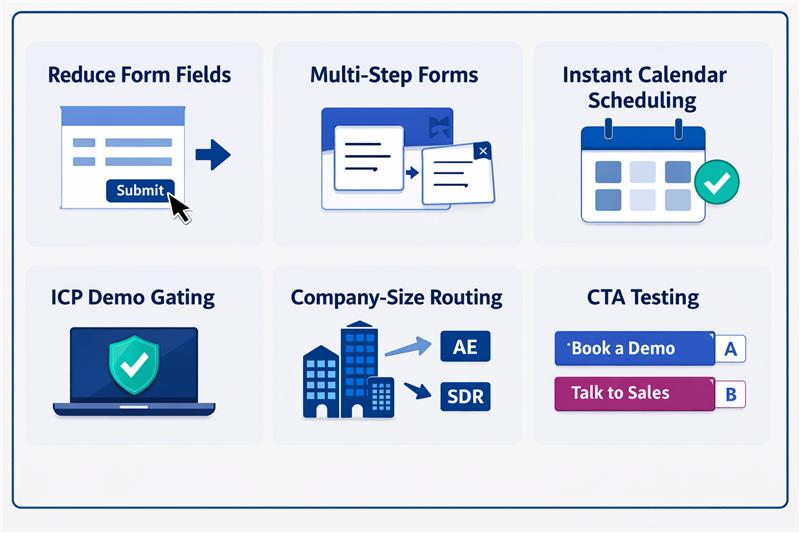
| Experiment | What changes | Conversion upside | Operational risk |
| Reduce form fields | Remove fields like company size or industry | Lower friction, higher submissions | Routing rules lose required inputs |
| Multi-step forms | Break long forms into steps | Higher completion rates | Partial data can break routing or CRM mapping |
| Instant calendar scheduling | Show rep calendars immediately | Faster meeting booking | Wrong routing exposes incorrect calendars |
| ICP demo gating | Allow scheduling only for qualified leads | Higher lead quality for sales | Qualification logic can conflict with routing |
| Company-size routing | Route enterprise leads to AEs | Faster sales response | Incorrect data misroutes territories |
| CTA testing | “Book a demo” vs “Talk to sales” | Higher click and submit rates | Intent signals may disrupt qualification workflows |
Read more: RAG vs Fine-Tuning: Cost, Compliance, and Scalability Explained
Demo request flows should be treated as sales infrastructure. The safest way to experiment is to separate the experimentation layer from the operational layer that controls routing, territories, calendars, and CRM workflows. When these layers remain independent, teams can test improvements without disrupting sales execution.
Routing systems depend on structured data fields to determine ownership, territory assignment, and follow-up workflows. Experiments should never remove or corrupt the inputs these systems require.
Reducing form friction is a common experiment, but routing systems still require company-level data. Enrichment allows teams to shorten forms while preserving operational inputs.
Running experiments across all traffic increases operational risk. Limiting tests to defined segments helps isolate potential failures without affecting the entire pipeline.
Build routing safeguards before running tests
Operational safeguards ensure leads continue to reach sales teams even if an experiment fails or routing logic behaves unexpectedly.
Monitor operational metrics
Demo flow experiments should not be judged solely on form conversion performance. Operational stability and sales efficiency must also be monitored.
Read more: Executive Guide to Measuring AI ROI and Payback Periods
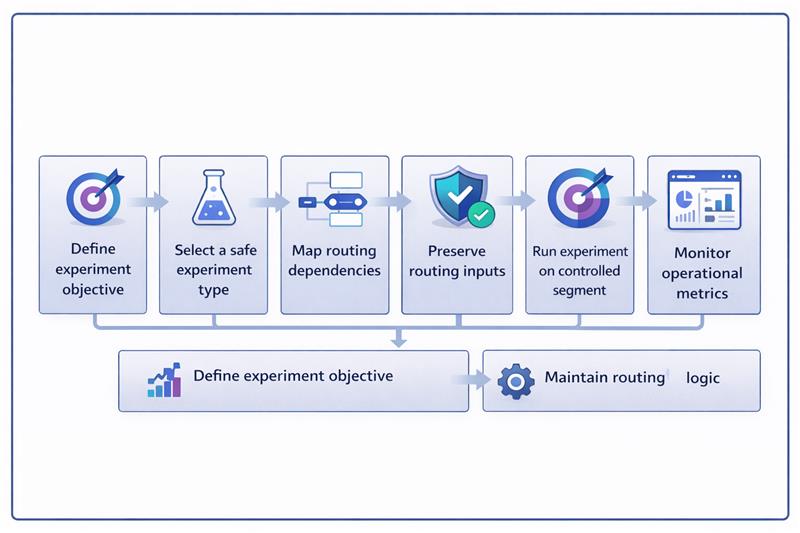
Running experiments on demo request flows requires a controlled workflow. The experiment should modify the user experience while keeping the routing, CRM mapping, and calendar systems unchanged.
The example below shows how a team tests a multi-step demo form while preserving routing inputs through enrichment and keeping backend assignment logic intact.
Read more: Why Enterprise AI Fails and How to Fix It
Demo request flows are deeply integrated with sales infrastructure. Routing engines, territory ownership rules, CRM workflows, and SDR calendars all depend on the data these forms generate. This is why many teams avoid experimentation altogether. The real challenge is how to experiment without disrupting the systems that turn demo requests into a pipeline.
When experimentation is separated from routing logic, teams can safely optimise these high-intent conversion points. Preserving routing inputs, using enrichment, running controlled experiments, and monitoring operational metrics allow improvements without operational risk. If your team wants to improve demo conversion without breaking sales systems, Linearloop helps design experimentation frameworks that protect routing logic while enabling continuous optimisation.
Mayur Patel
Mar 9, 20266 min read
