We're officially a Great Place To Work® certified company, India | 2026–27
Mayur Patel
Jan 6, 2026
6 min read
Last updated Jan 6, 2026

If you are running or building a B2B marketplace for spare parts, you already know this problem does not start with search.
You can improve relevance, add filters, tweak ranking logic, and still watch buyers struggle to find the right part because the catalog cannot express what the buyer actually needs. Compatibility, context, specifications, and replacement logic get lost in SKU names and free-text descriptions.
At a certain scale, spare parts discovery stops being a UX problem and becomes a catalog architecture problem. This is usually the point where teams start evaluating attribute-rich catalog structures.
This blog breaks down when attribute-rich catalogs make sense, what committing to them really changes, and how to approach the shift without over-engineering your marketplace.
Also Read: Why SLO-Driven Auto-Scaling Outperforms Traditional Metrics
Most teams do not decide to redesign their catalog structure upfront. The decision is usually forced by a pattern of signals that keep repeating, even after search and UX improvements.
If you are seeing more than one of the following consistently, the issue is no longer tactical. It is structural.
Also Read: Managing bulk pricing and logistics for construction B2B marketplaces
Moving to attribute-led discovery changes how your marketplace understands products, buyers, and scale.
Attributes stop being supplementary data and become the primary way parts are represented, indexed, and compared. Discovery logic shifts from matching text to resolving constraints. Compatibility, specifications, and usage context become first-class inputs.
This commitment also changes how teams work. Product decisions move upstream into catalog design. Engineering effort shifts from continuous relevance tuning to building durable data structures. Supplier onboarding evolves from SKU ingestion to attribute alignment. Sales and support stop compensating for discovery gaps and start relying on the system.
Most importantly, the marketplace stops guessing what the buyer means and starts knowing what qualifies a part as correct.
Teams at this stage are deciding whether they are ready to make attributes foundational to discovery rather than supportive of it.
Also Read: B2B Marketplace Logistics Workflow (End-to-End Workflow)
The value of attribute-rich catalogs show up in how buyers behave once discovery becomes reliable.
When parts can be filtered and compared based on compatibility and constraints, buyers move faster and with more confidence. They stop double-checking through sales or support. They stop over-ordering to reduce risk. Repeat procurement becomes easier because discovery feels predictable rather than uncertain.
On the supply side, attribute richness reduces the hidden cost of scale. As more suppliers and SKUs are added, discovery quality does not degrade at the same rate. The marketplace can absorb catalog growth without proportional increases in support, curation, or manual intervention.
Over time, this compounds into tangible outcomes. Shorter sourcing cycles. Higher self-serve completion. Better repeat usage from the same buyer accounts. Fewer stalled transactions caused by uncertainty around part fit or interchangeability.
Attribute richness is about capturing what the marketplace needs to function reliably at scale. The wrong depth either breaks discovery or slows the system down.
Decision-stage teams typically anchor this choice around a few non-negotiables.
Also Read: The Innovation-Ready Engineering Culture: A Practical Guide
Attribute schemas fail when new categories are added, suppliers diversify, or discovery use cases evolve. Schemas that survive are designed for change.
The table below outlines the core design principles teams use to keep attribute schemas flexible without losing control.
| Schema design principle | What it means in practice | Why it matters at scale |
| Controlled flexibility | Core attributes remain standardised, while category-specific and optional attributes allow variation without breaking structure | Prevents fragmentation while still supporting diverse spare part categories |
| Attribute inheritance | Shared attributes are defined at a parent or family level and inherited by related parts | Reduces duplication and keeps large catalogs maintainable as they grow |
| Optional versus mandatory attributes | Only attributes critical to discovery and compatibility are enforced as mandatory | Keeps supplier onboarding fast without compromising discovery quality |
| Versioned schemas | Attribute definitions evolve through versioning rather than replacement | Allows the catalog to change without forcing disruptive rework |
| Explicit data types and units | Attributes use consistent data types, units, and formats | Improves filter accuracy, search relevance, and attribute comparability |
| Decoupled attribute services | Attribute logic is separated from the presentation and search layers | Enables independent evolution of catalog, discovery, and UI systems |
Supplier data is where most attribute strategies either stall or succeed. No marketplace gets clean, complete attributes at the point of ingestion, especially in spare parts.
Decision-stage teams usually shift from expecting perfect data to designing systems that can absorb imperfection. This means separating supplier-provided attributes from internal attribute definitions, allowing mapping and normalisation without blocking onboarding. It also means accepting progressive enrichment as a first-class workflow, not a fallback.
Attribute-rich catalogs work when suppliers can start with what they have, while the marketplace steadily improves structure and consistency over time. Validation rules focus on discovery-critical attributes. Everything else can be completed or corrected as usage patterns emerge.
The goal is to prevent messy data from leaking into discovery in ways that undermine buyer trust.
Interchangeability is where spare parts discovery becomes operationally complex. The same functional requirement can be met by multiple parts across brands, versions, or production timelines. Keyword search is not designed to handle that complexity.
Attribute-rich catalogs allow marketplaces to model these relationships explicitly. Original parts, alternates, equivalents, and superseded versions can be linked through shared attributes rather than inferred through naming conventions. Compatibility becomes a rule.
For decision-stage teams, the key shift is treating interchangeability as a catalog concern, not a sales workaround. Once these relationships are structured, buyers gain options without losing confidence, and the marketplace can scale choice without scaling confusion.
This is often the moment when attribute investment starts paying for itself in real, measurable ways.
Search, filters, and attributes often evolve as separate investments. At scale, that separation becomes a liability.
In attribute-led discovery, search acts as an entry point, not the decision engine. Keyword queries surface a relevant universe of parts. Attributes then take over, narrowing options based on compatibility, specifications, and constraints. Filters stop being cosmetic controls and start reflecting real buying requirements.
This alignment changes how teams invest. Relevance tuning becomes less fragile because it is grounded in structured data. Filters remain useful even as the catalog grows. Search stops compensating for missing structure.
For decision-stage teams, the question is whether search, filters, and attributes are designed to reinforce each other rather than cover for each other’s gaps.
Attribute-rich catalogs fail because ownership is unclear.
At scale, attributes sit at the intersection of product intent, engineering implementation, and operational reality. Without explicit ownership, definitions drift, exceptions accumulate, and discovery quality degrades quietly over time.
Decision-stage teams usually formalize governance early. The product owns which attributes matter for discovery; engineering owns how those attributes are represented and enforced; catalog or operations teams own data quality and day-to-day integrity. Changes move through a defined process rather than ad-hoc fixes.
Attribute systems only become an advantage when they remain reliable long after the initial implementation.
There is no default architecture for attribute-rich catalogs. The right approach depends on scale, complexity, and the degree to which discovery is central to the marketplace.
Some teams extend existing PIMs to support richer attribute models, while others introduce a dedicated attribute or catalog service that sits between suppliers, search, and the frontend. In more complex setups, attributes become a shared service consumed by search, recommendations, and downstream systems.
Each option comes with trade-offs. PIM-led approaches reduce initial effort but can limit flexibility. Custom services offer control but require stronger engineering ownership. Hybrid models add complexity but scale better across evolving use cases.
The priority here is ensuring attributes are treated as first-class entities that can evolve without forcing repeated rewrites of discovery, search, or UI layers.
Most attribute-rich catalog initiatives fail when teams try to do everything at once. Successful implementations are staged, deliberate, and tied to real discovery problems.
Decision-stage teams typically move through a sequence like this.
Attribute-rich catalogs are not a discovery feature. They are discovery infrastructure.
For spare parts marketplaces, this distinction matters. As catalogs grow and suppliers diversify, discovery cannot rely on search tuning or manual intervention to keep up. It needs structure that scales with complexity rather than fighting it.
Teams that invest here are building a foundation that allows discovery, compatibility, and confidence to compound over time. Search improves because the data improves. Buyer trust increases because the system becomes predictable.
The question is no longer whether attribute richness is useful. It is whether the marketplace is ready to treat discovery as infrastructure rather than a layer that can be patched later.
Mayur Patel, Head of Delivery at Linearloop, drives seamless project execution with a strong focus on quality, collaboration, and client outcomes. With deep experience in delivery management and operational excellence, he ensures every engagement runs smoothly and creates lasting value for customers.

Enterprise Headless CMS: What to Assess Before You Shortlist a Platform
An enterprise headless CMS separates content storage from the front end that displays it, delivering content through an API so the same content can power a website, a mobile app, or any other channel independently. Choosing the right one depends on three things: how many channels your content actually needs to reach; how much front-end engineering capacity your team can commit long-term; and how complex your governance requirements are across regions or business units.
Most vendor conversations start with a feature list. That is the wrong entry point, because features do not tell you whether your organisation can actually sustain the platform once it is live. This guide covers the evaluation framework we walk enterprise teams through before any shortlist gets built, the structural comparison between platform models, and the decision logic that follows from it.
Also Read: Why Some Lead Form Fields Kill Conversions (And Which Ones Actually Help)
An enterprise CMS is a content management system built to handle the volume, governance, security and integration complexity that a single site or small business CMS is not designed for. Multiple brands, regions, approval chains and content types are the norm, not the exception. Whether that enterprise CMS should be headless, hybrid or traditional is a separate decision, and it is the one this guide answers.
Headless CMS means separating content storage from the front end that displays it, so the same content reaches a website, an app or any other channel through an API instead of a built-in template. A traditional CMS renders the page itself. A headless CMS hands content to whatever system asks for it, and that system decides how to display it.
A hybrid CMS, where platforms like dotCMS sit, keeps that API-first content layer but adds an optional front end and visual editing tools on top so marketing teams are not left waiting on engineering for every page change.
The distinction changes who owns the decision. A traditional CMS choice is largely a marketing and content operations call. A headless CMS choice is an architecture decision with marketing consequences, and it needs both functions in the room from day one.
Also Read: B2B Marketplace Logistics Workflow (End-to-End Workflow)
If the honest answer is one website, the case for headless is weaker than any headless platform's sales page will admit. Headless earns its complexity when content genuinely needs to reach multiple surfaces.
Enterprise content rarely takes one shape. A product page, a regulatory disclosure and a campaign landing page each need different fields, relationships and governance. Evaluate a platform's content modelling against your actual content types, not the demo's blog post example.
Response times, caching behaviour and rate limits under real traffic are where headless platforms diverge most from their marketing claims. Ask for load tested numbers on content structures similar to yours, not published benchmarks on a blank content model.
This is the most common regret in headless migrations. Pure API-first platforms can leave marketing teams dependent on engineering for changes that used to take five minutes. A hybrid layer or a well-built preview and editing experience is not a nice to have at enterprise scale. It is the difference between adoption and a shelved project.
Role-based permissions, approval workflows and localisation need to be assessed against your actual organisational structure, including the parts of it that are politically inconvenient to model. A platform that assumes one content team, one brand and one approval chain will not survive contact with a matrixed enterprise.
Content rarely lives alone. If product data, digital asset management or personalisation engines are already in place, the CMS has to integrate cleanly with them, not force a rebuild of adjacent systems that already work.
Vendor lock-in in headless CMS is quieter than in traditional platforms. It shows up in proprietary query languages, custom field types with no export path, and content models that only make sense inside one vendor's schema. Ask this before signing, not during the exit.
Implementation, custom front-end development, ongoing engineering support and migration efforts usually outweigh licensing costs over three years. A cheaper licence with a heavier build is not automatically the cheaper decision. Model the fully loaded cost across a three-year horizon before comparing quotes.
Also Read: Building a B2B Marketplace: Complete Blueprint for Scale, Trust, and Liquidity
The category splits into three architectural models, not a single spectrum of "more or less headless". Understanding which model a platform belongs to tells you more than any feature checklist.
Model | Representative Platforms | Strongest For | Weakest For |
Traditional monolithic | Adobe Experience Manager (legacy mode), WordPress (default) | Single-channel sites needing fast launch and minimal engineering overhead | Multi-channel delivery, API-first integrations, scaling past one front end |
Pure headless | Contentful, Sanity | Maximum channel flexibility, engineering-led teams building custom front ends | Editorial independence, out-of-the-box governance, teams without dedicated front-end resources |
Hybrid | dotCMS, Storyblok | Balancing API-first architecture with a working front end and visual editing | Teams needing extreme customisation beyond what the hybrid layer exposes |
The comparison that matters is not which platform has more features. It is which architectural model matches your organisation's actual engineering capacity and channel ambition. A pure headless platform in the hands of a marketing-led team with no dedicated front-end engineers will underperform a hybrid platform on time to value, regardless of API quality.
Within the hybrid category, dotCMS's position is specific. Content architecture is API-first from the ground up, but the platform ships with enough front-end and visual editing capability that marketing teams retain publishing independence. That trade-off is why it tends to fit enterprise teams that want headless-grade flexibility without building and maintaining a bespoke front end and editorial layer from scratch. You can see how this plays out in practice on our dotCMS partnership page.
Rather than scoring platforms feature by feature, work through this sequence.
If no, a traditional CMS is likely the correct answer, and the rest of this framework is premature. If yes, proceed.
If yes, a pure headless platform becomes viable, and API architecture and content modelling flexibility should carry the most weight in your evaluation. If no, proceed to hybrid platforms and weight editorial independence more heavily than raw API flexibility.
If governance is simple, most hybrid and headless platforms will satisfy it. If governance is complex, this becomes a disqualifying filter before cost or features are even discussed. Request a governance model walkthrough against your actual org chart before any commercial conversation.
Heavy integration load favours platforms with mature, documented APIs and existing connectors to your specific stack over platforms with broader but shallower integration claims.
Before signing, confirm content export format, whether custom field types are portable, and what a migration off the platform would realistically require. This is the question every vendor conversation skips and the one every failed migration wishes had been asked earlier.
The trade-off underneath all five steps is the same one: flexibility against build effort. A pure headless platform maximises flexibility and asks the most of your engineering team. A traditional platform minimises build effort and caps your channel ceiling. A hybrid platform trades a slice of flexibility for a working editorial layer, which is usually the correct trade for enterprise teams that need to move on content without a permanent squad dedicated to CMS infrastructure.
Also Read: How B2B Marketplaces Can Attract, Qualify, and Convert High-Value Buyers
Most enterprise buyers researching this topic are not starting from zero. They are running an existing CMS and deciding whether, and how, to move. The migration follows a predictable lifecycle, and where it breaks down is consistent across projects.
Catalogue existing content types, volume, and every system currently integrated with the CMS, including the undocumented ones. Most timelines go wrong here, because the audit is treated as a formality rather than the foundation for everything after it.
Rebuild the content architecture for the target platform before touching migration tooling. A content model copied directly from the old system replicates its constraints rather than solving them.
Migrate in stages, keeping the existing front end live wherever possible while the content layer is rebuilt underneath it. A full rebuild that goes live in one cutover carries more risk than the timeline pressure to do it that way usually accounts for.
Train content teams on the new publishing workflow before decommissioning the old system, not after. This is the stage most technical migration plans underwrite, and the one that determines whether the new platform gets adopted or quietly worked around.
A phased migration that keeps a working front end in place while the content architecture is rebuilt underneath it is, in most enterprise contexts, faster to production and materially lower risk than a full rebuild attempted in one pass.
This is the same framework we use as a dotCMS implementation partner when a client is deciding between a full headless rebuild and a phased migration that preserves a working front end while the content architecture is rebuilt underneath it. The right answer has depended less on the platform's feature list and more on how much appetite the organisation has for owning a custom front end and how urgently new channels need to ship.
The teams that get the most value from a headless or hybrid migration are the ones that work through the eight questions and the decision tree honestly before they see a single demo, because a demo will always look capable. The gap between a demo and a production system at enterprise scale is exactly where these questions live.
If your team is weighing a headless or hybrid CMS migration and the framework above raises more uncertainty than clarity, that is normal at this stage. Our team can walk through your specific content architecture and integration landscape on a call and help you work out where you actually sit on the flexibility versus build effort trade-off before you shortlist vendors.
Mayank Patel
Jul 6, 20265 min read
")
Why Some Lead Form Fields Kill Conversions (And Which Ones Actually Help)
Most B2B funnels break at the form. Teams keep adding fields like company size, job title, phone number, and budget, hoping better data will improve lead quality. Instead, conversion rates drop and demo requests slow down. What started as a qualification step becomes a friction point. Every additional field increases effort, hesitation, or privacy concerns, quietly pushing legitimate prospects away before they ever submit the form.
Lead forms sit at the centre of the funnel, which creates a constant trade-off. Collect too little information, and sales receive unqualified leads. Collect too much, and potential customers abandon the form. The real challenge is knowing which fields genuinely improve qualification and which ones only create friction. This blog breaks down that difference and explains how to design forms that capture leads without hurting conversions.
Read more: Why Enterprise AI Fails and How to Fix It
Most long lead forms are not designed intentionally. They grow over time. The form becomes a place for data collection rather than a mechanism for moving prospects through the funnel. Understanding why teams add these fields is the first step to identifying which ones actually create value.
Read more: Executive Guide to Measuring AI ROI and Payback Periods
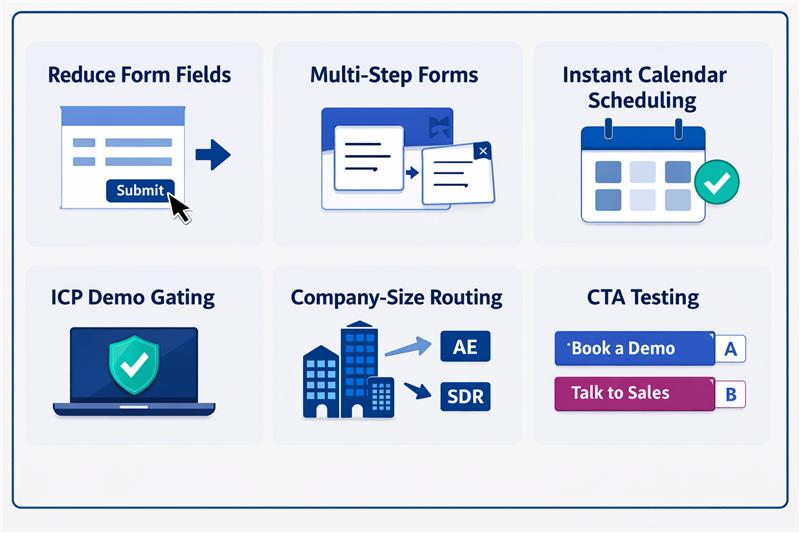
Most B2B teams design forms with a single objective: To improve lead quality. Additional fields are added to capture firmographic data, assess intent, or help sales prioritise outreach. Over time, the form becomes longer, the questions become more detailed, and the assumption remains the same: more information should produce better leads.
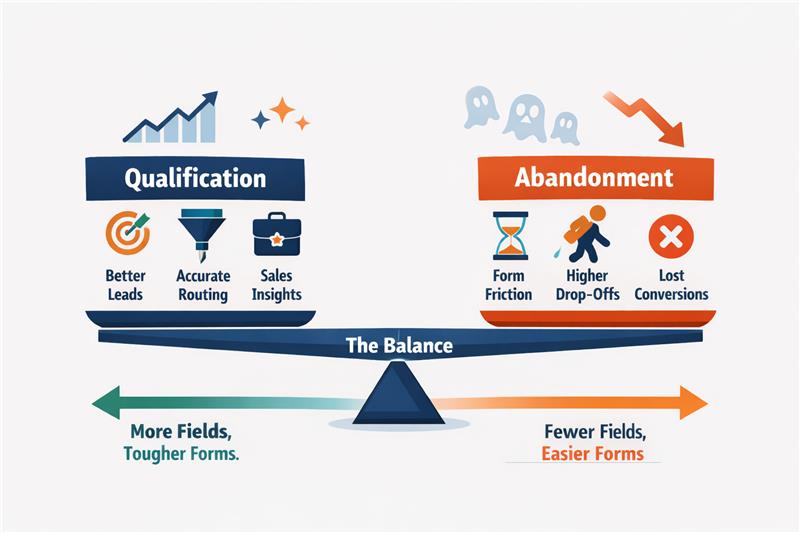
This is where the core trade-off emerges.
Understanding this trade-off helps teams evaluate whether a field actually improves decision-making or simply adds friction.
| Aspect | Qualification | Abandonment |
| Definition | The process of identifying whether a lead fits the company’s ideal customer profile or purchasing potential. | The point at which a user leaves the form without submitting it. |
| Purpose in the funnel | Helps sales prioritise leads and allocate time to higher-value opportunities. | Reduces the number of captured leads, weakening the top of the funnel. |
| Typical triggers | Fields like company name, job title, or company size that provide useful context for sales teams. | Long forms, sensitive questions, or complex dropdowns that increase effort or discomfort. |
| User perception | Users feel they are providing relevant information to request a demo or contact sales. | Users feel the form requires too much effort or asks for unnecessary personal or company data. |
| Impact on conversion rates | Moderate qualification fields may slightly reduce conversions but improve lead quality. | Excessive or poorly chosen fields significantly increase drop-off rates. |
| Design implication | Fields should only exist if they help a meaningful sales or routing decision. | Any field that does not influence decisions becomes unnecessary friction. |
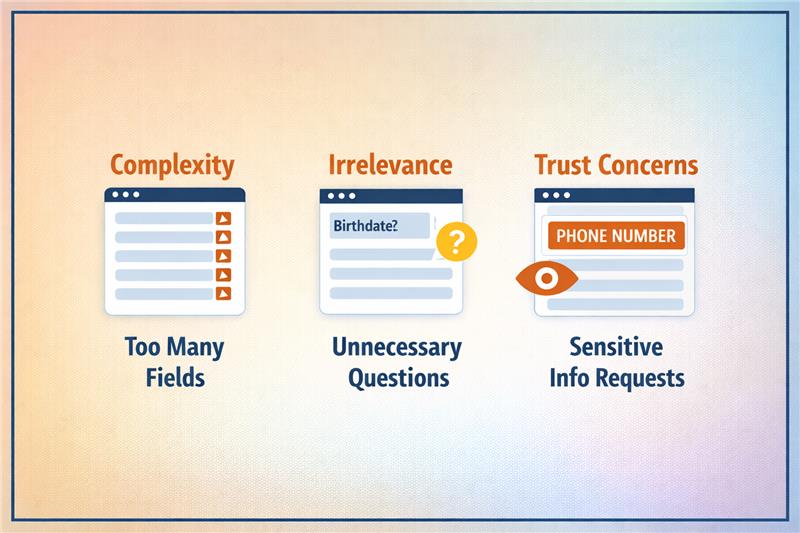
Form abandonment happens when the form introduces friction that feels unnecessary or uncomfortable. Small moments of hesitation accumulate as the user progresses through the form. When the perceived effort becomes higher than the expected value, users exit the flow.
Three behavioural triggers typically drive this drop-off:
Some fields immediately create hesitation because users worry about how the information will be used. Questions that appear sensitive or intrusive increase perceived risk before trust is established.
Trigger: Fields such as phone numbers, revenue ranges, or personal contact details raise concerns about unwanted sales calls or data misuse, prompting users to abandon the form.
Certain questions require users to pause, think, or estimate information they may not know immediately. When a form demands too much mental effort, the completion process slows down.
Trigger: Complex dropdown menus, unclear categories, or questions like company revenue or employee ranges increase cognitive load and discourage users from finishing the form.
Some information is useful later in the sales process but appears too early in the initial conversion step. When advanced qualification questions appear prematurely, users feel they are entering a long evaluation process.
Trigger: Asking detailed requirements, budget ranges, or implementation timelines during the first interaction creates friction because the user has not yet committed to deeper engagement.
The goal is not to eliminate qualification from the form but to focus on fields that deliver decision value without creating unnecessary resistance. When forms prioritise these signals, teams gain useful context while keeping the submission experience manageable for the user.
Read more: How to Deploy Private LLMs Securely in Enterprises
Identifying and removing the right form fields reduce friction while maintaining the information that genuinely supports qualification.
Read more: How to Deploy Private LLMs Securely in Enterprises

The most practical approach is to assess every form field through a signal versus friction lens. Signal represents the decision value the field provides, while friction represents the effort or hesitation it introduces for the user. When teams analyse fields using this framework, it becomes easier to separate necessary qualification questions from unnecessary data requests.
Read more: Modern AI Data Stack Architecture Explained for Enterprises
The objective is to understand how each field affects both conversion behaviour and downstream pipeline outcomes. This requires measuring not only form completion rates but also how those leads progress through the sales process. When testing is done carefully, teams can improve conversion rates without sacrificing qualification quality.
Read more: Personalization vs Borad UX Changes in Conversion Rate Optimization Services
Lead forms should capture decisions, not excess data. Every field must justify its presence by improving routing, prioritisation, or sales context. When forms collect information that does not influence these decisions, friction increases and conversion rates drop. The most effective funnels focus on a small set of high-signal fields that capture intent without slowing users down.
Improving forms requires a disciplined approach: evaluate each field for signal, test changes carefully, and measure both conversion rates and downstream pipeline outcomes. When designed correctly, forms become a fast entry point rather than a barrier. If your funnel is struggling with form friction or qualification trade-offs, Linearloop helps teams design and optimise conversion flows that improve both lead capture and pipeline quality.
Mayur Patel
Mar 11, 20266 min read